我们在上文简述了DQN算法。此文以PyTorch来实现一个DQN的例子。我们的环境选用CartPole-v1。我们的输入是一幅图片,动作是施加一个向左向右的力量,我们需要尽可能的保持木棍的平衡。
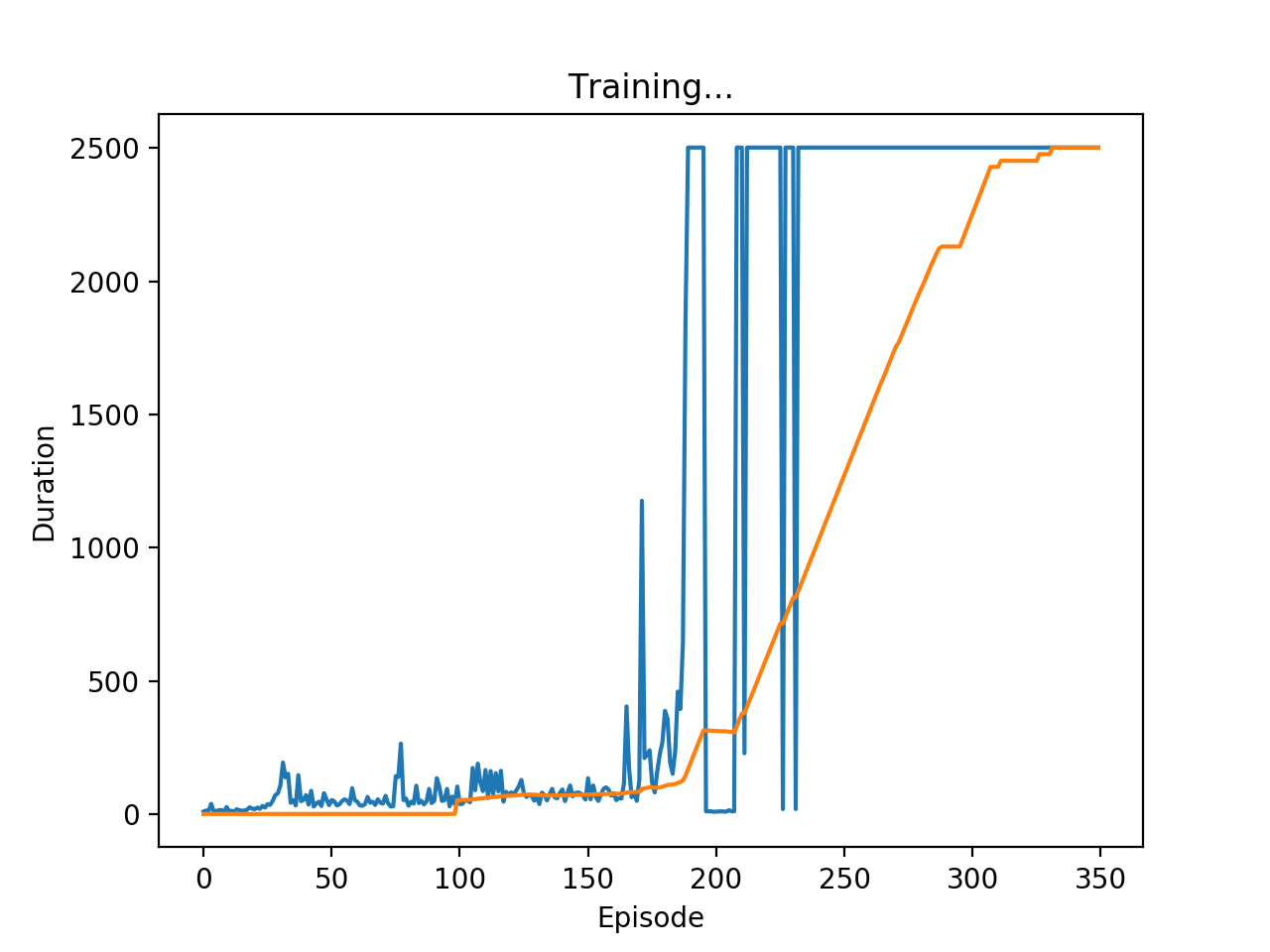
对于这个环境,尝试了很多次,总是不能达到很好的效果,一度怀疑自己的代码写的有问题。后来仔细看了这个环境的奖励,是每一帧返回奖励1,哪怕是最后一帧也是返回1 的奖励。这里很明显是不合理的俄。我们需要重新定义这个奖励函数,也就是在游戏结束的时候,给一个比较大的惩罚,r=-100。很快可以达到收敛。
Replay Memory
1 | Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward')) |
Q网络
1 | class DQN(nn.Module): |
初始化参数和状态
1 | import gym |
探索和选择最佳动作
1 | steps_done = 0 |
优化模型(关键代码)
这里主要是抽样、目标值计算、损失计算的部分。损失计算采用Huber loss。
1 | def optimize_model(): |
训练循环
这里主要有主循环、获取输入、记录回放、训练、复制参数等环节。
1 | num_episodes = 1000 |