本文假设读者已经了解了CNN的基本原理。在实际的项目中,会发现CNN有多个参数需要调整,本文主要目的在于理清各个参数的作用。
卷积核 kernel
Kernel,卷积核,有时也称为filter。在迭代过程中,学习的结果就保存在kernel里面。深度学习,学习的就是一个权重。kernel的尺寸越小,计算量越小,一般选择3x3,更小就没有意义了。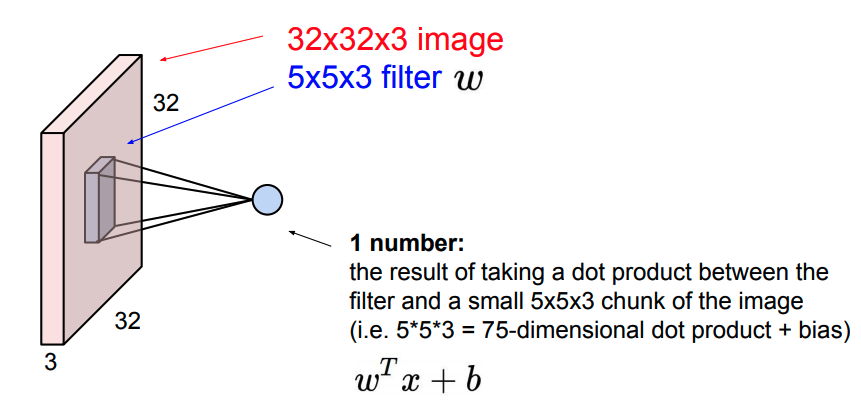
结果是对卷积核与一小块输入数据的点积。
层数 Channels
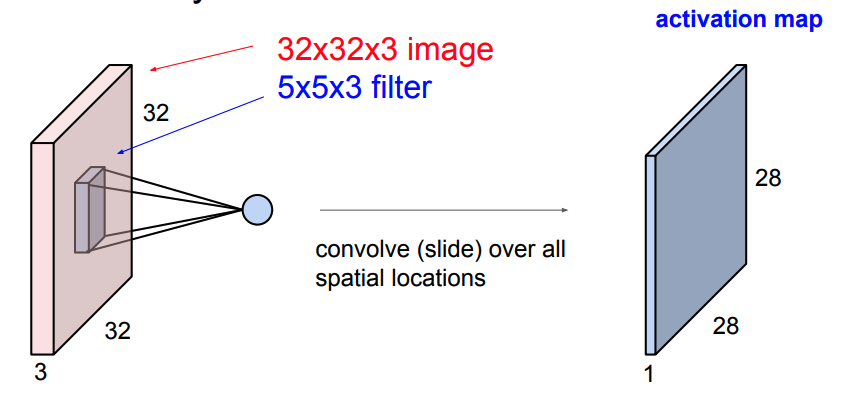
所有位置的点积构成一个激活层。
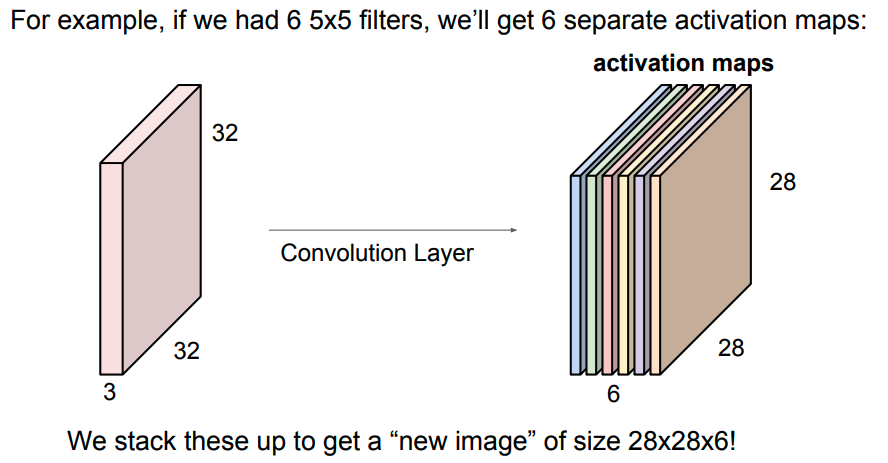
如果我们有6个卷积核,我们就会有6个激活层。
步长 Stride
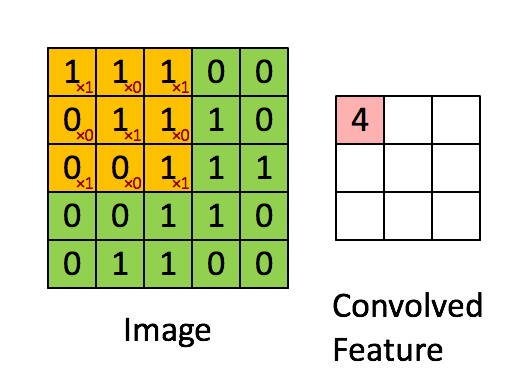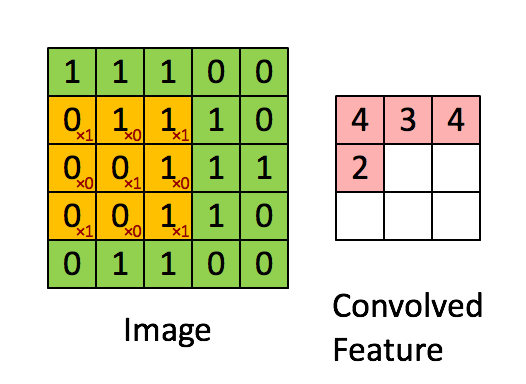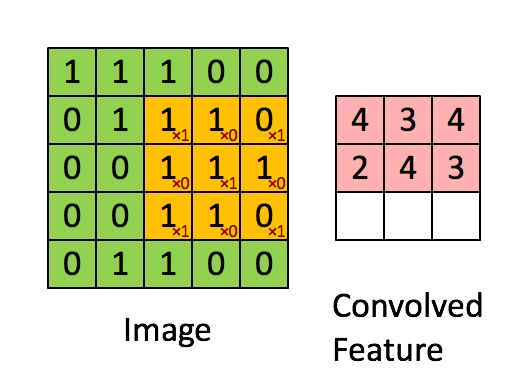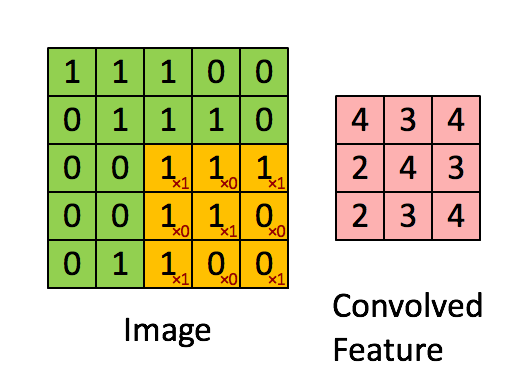
上图是每次向右移动一格,一行结束向下移动一行,所以stride是1x1,如果是移动2格2行则是2x2。
填充 Padding
Padding的作用是为了获取图片上下左右边缘的特征。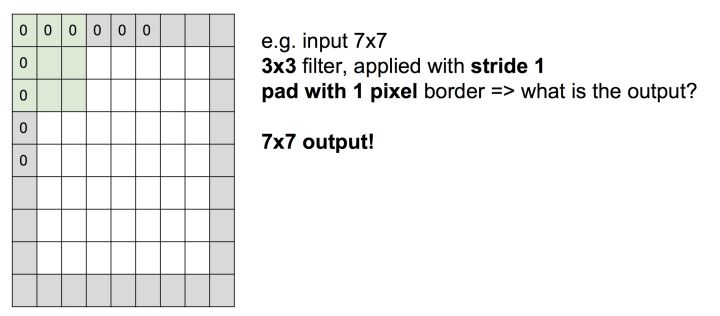
池化 Pooling
卷积层为了提取特征,但是卷积层提取完特征后特征图层依然很大。为了减少计算量,我们可以用padding的方式来减小特征图层。Pooling的方法有MaxPooling核AveragePooling。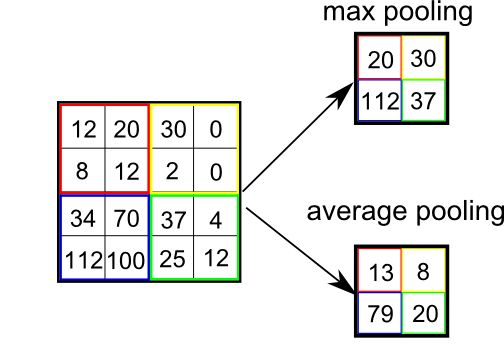
推荐看一下李飞飞的这篇slide
PyTorch 中的相关方法
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=’zeros’)
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
- stride 默认与kernel_size相等
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)
Tensor.view(*shape) -> Tensor
- 用于将卷积层展开为全连接层
1
2
3
4
5
6
7
8
9>>> x = torch.randn(4, 4)
>>> x.size()
torch.Size([4, 4])
>>> y = x.view(16)
>>> y.size()
torch.Size([16])
>>> z = x.view(-1, 8) # the size -1 is inferred from other dimensions
>>> z.size()
torch.Size([2, 8])
- 用于将卷积层展开为全连接层
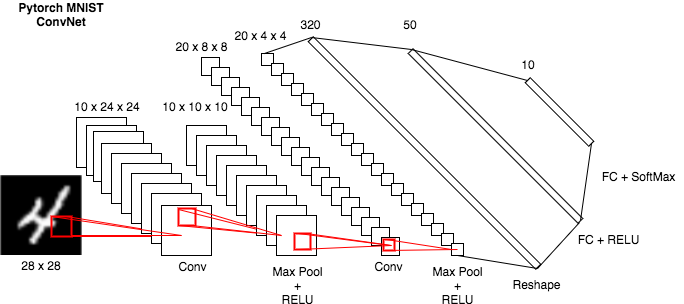
MNIST例子
MNIST 数据集的输入是 1x28x28 的数据集。在实际开发中必须要清楚每一次的输出结构。
- 我们第一层使用 5x5的卷积核,步长为1,padding为0,28-5+1 = 24,那么输出就是 24x24。计算方法是 (input_size - kernel_size)/ stride + 1。
- 我们第二层使用 2x2的MaxPool,那么输出为 12x12.
- 第三层再使用5x5,卷积核,输出则为 12-5+1,即 8x8。
- 再使用 2x2 MaxPool,输出则为 4x4。
1 | import torch.nn as nn |